python, 전처리, 통계, 가설검정, 기계학습, 회귀, 분류, 군집, 모델 학습, 모델 평가
특성 선택(Feature Selection)은 모델 학습에 사용되는 입력 변수 중에서 중요한 특성만 선별하는 과정이다. 모든 변수를 사용하는 것이 항상 최선은 아니며, 불필요하거나 중복된 특성은 오히려 모델 성능을 저하시키고 과적합을 유발할 수 있다. 이 장에서는 필터(Filter), 래퍼(Wrapper), 임베디드(Embedded) 방법의 원리와 실무 적용 전략을 학습한다.
예제: 데이터 로드
import seaborn as snsimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split# 데이터 로드df = sns.load_dataset("penguins").dropna()# 특성과 타겟 준비X = df[["bill_length_mm", "bill_depth_mm", "flipper_length_mm", "body_mass_g"]]y = df["species"]print("데이터 크기:", df.shape)print("특성 개수:", X.shape[1])print("타겟 클래스:", y.unique())
데이터 크기: (333, 7)
특성 개수: 4
타겟 클래스: <StringArray>
['Adelie', 'Chinstrap', 'Gentoo']
Length: 3, dtype: str
20.1 특성 선택의 개념과 필요성
특성 선택은 데이터의 차원을 줄이고 모델 성능을 향상시키는 핵심 기법이다.
특성 선택의 목적
목적
설명
효과
모델 성능 향상
과적합 감소, 일반화 성능 향상
테스트 정확도 증가
학습 시간 단축
변수 수 감소로 계산량 감소
실험 속도 향상
해석력 향상
중요 변수만 사용하여 이해 쉬움
비즈니스 인사이트 도출
차원의 저주 방지
고차원 데이터 문제 완화
샘플 수 대비 변수 수 적절화
다중공선성 제거
상관성 높은 변수 제거
모델 안정성 향상
비용 절감
데이터 수집/저장/처리 비용 감소
실무 효율성 증가
특성이 많을 때의 문제
문제
설명
차원의 저주
변수가 많아질수록 필요한 샘플 수가 기하급수적 증가
과적합
노이즈 변수가 학습에 포함되어 일반화 실패
계산 비용
학습 시간과 메모리 사용량 증가
다중공선성
상관성 높은 변수들이 모델 불안정하게 만듦
해석 어려움
변수가 많아 중요 요인 파악 곤란
20.1.1 특성 선택 vs 특성 추출
혼동하기 쉬운 개념을 명확히 구분한다.
특성 선택 vs 특성 추출 비교
구분
특성 선택 (Feature Selection)
특성 추출 (Feature Extraction)
정의
기존 변수 중 일부를 선택
기존 변수를 변환하여 새로운 변수 생성
변수 의미
유지됨
변경됨 (조합/변환)
해석력
높음
낮음
예시
100개 중 10개 선택
PCA로 10개 주성분 생성
대표 방법
상관계수, RFE, Lasso
PCA, t-SNE, Autoencoder
원본 변수
그대로 사용
변환하여 사용
예제: 특성 선택 vs 특성 추출
from sklearn.decomposition import PCAfrom sklearn.feature_selection import SelectKBest, f_classif# 특성 선택: 원본 변수 중 k개 선택selector = SelectKBest(score_func=f_classif, k=2)X_selected = selector.fit_transform(X, y)selected_features = X.columns[selector.get_support()]print("=== 특성 선택 ===")print(f"선택된 변수: {selected_features.tolist()}")print(f"결과 차원: {X_selected.shape}")# 특성 추출: 새로운 변수 생성pca = PCA(n_components=2)X_pca = pca.fit_transform(X)print("\n=== 특성 추출 (PCA) ===")print(f"주성분 변수: PC1, PC2")print(f"결과 차원: {X_pca.shape}")print(f"설명 분산 비율: {pca.explained_variance_ratio_}")
=== 특성 선택 ===
선택된 변수: ['bill_length_mm', 'flipper_length_mm']
결과 차원: (333, 2)
=== 특성 추출 (PCA) ===
주성분 변수: PC1, PC2
결과 차원: (333, 2)
설명 분산 비율: [9.99893229e-01 7.82232504e-05]
20.2 특성 선택 방법의 분류
특성 선택 방법은 크게 세 가지로 분류된다.
특성 선택 방법 분류
방법
모델 사용
계산 비용
성능
특징
필터 (Filter)
사용 안 함
낮음
중간
통계량 기반, 빠름
래퍼 (Wrapper)
사용함
매우 높음
높음
모델 성능 기반, 느림
임베디드 (Embedded)
사용함
중간
높음
학습 과정에 내장
20.3 필터(Filter) 방법
필터 방법은 모델을 사용하지 않고 데이터의 통계적 특성만으로 각 특성을 독립적으로 평가한다.
필터 방법의 특징
장점
단점
계산 속도가 매우 빠름
변수 간 상호작용 고려 못함
모델과 무관하게 사용 가능
모델별 최적화 불가
대용량 데이터에 적합
성능이 래퍼보다 낮을 수 있음
과적합 위험 낮음
단순한 선형 관계만 파악
20.3.1 분산 기반 선택
분산이 거의 없는 변수는 정보량이 적으므로 제거한다.
예제: 분산 기반 선택
from sklearn.feature_selection import VarianceThreshold# 데이터에 분산이 낮은 변수 추가 (예시)X_with_low_var = X.copy()X_with_low_var['constant_feature'] =1# 분산 = 0X_with_low_var['low_variance_feature'] = np.random.uniform(3.9, 4.1, len(X))print("=== 분산 확인 ===")print(X_with_low_var.var().sort_values())# 분산 임계값 설정 (분산 < 0.1인 변수 제거)selector = VarianceThreshold(threshold=0.1)X_high_var = selector.fit_transform(X_with_low_var)print(f"\n원본 변수 수: {X_with_low_var.shape[1]}")print(f"선택된 변수 수: {X_high_var.shape[1]}")print(f"제거된 변수: {X_with_low_var.columns[~selector.get_support()].tolist()}")
=== 분산 확인 ===
constant_feature 0.000000
low_variance_feature 0.003226
bill_depth_mm 3.877888
bill_length_mm 29.906333
flipper_length_mm 196.441677
body_mass_g 648372.487699
dtype: float64
원본 변수 수: 6
선택된 변수 수: 4
제거된 변수: ['constant_feature', 'low_variance_feature']
20.3.2 상관계수 기반 선택
타겟 변수와의 상관관계를 측정하여 중요한 변수를 선택한다.
예제: 상관계수 기반 선택
# 분류 문제를 위해 타겟을 수치형으로 변환from sklearn.preprocessing import LabelEncoderle = LabelEncoder()y_encoded = le.fit_transform(y)# 각 특성과 타겟 간 상관계수 계산correlations = {}for col in X.columns: corr = np.corrcoef(X[col], y_encoded)[0, 1] correlations[col] =abs(corr)# 상관계수로 정렬corr_df = pd.DataFrame({'Feature': list(correlations.keys()),'Correlation': list(correlations.values())}).sort_values('Correlation', ascending=False)print("=== 타겟과의 상관계수 ===")print(corr_df)# 시각화plt.figure(figsize=(10, 5))plt.barh(corr_df['Feature'], corr_df['Correlation'])plt.xlabel('Absolute Correlation with Target')plt.title('Feature Correlation with Target')plt.tight_layout()plt.show()
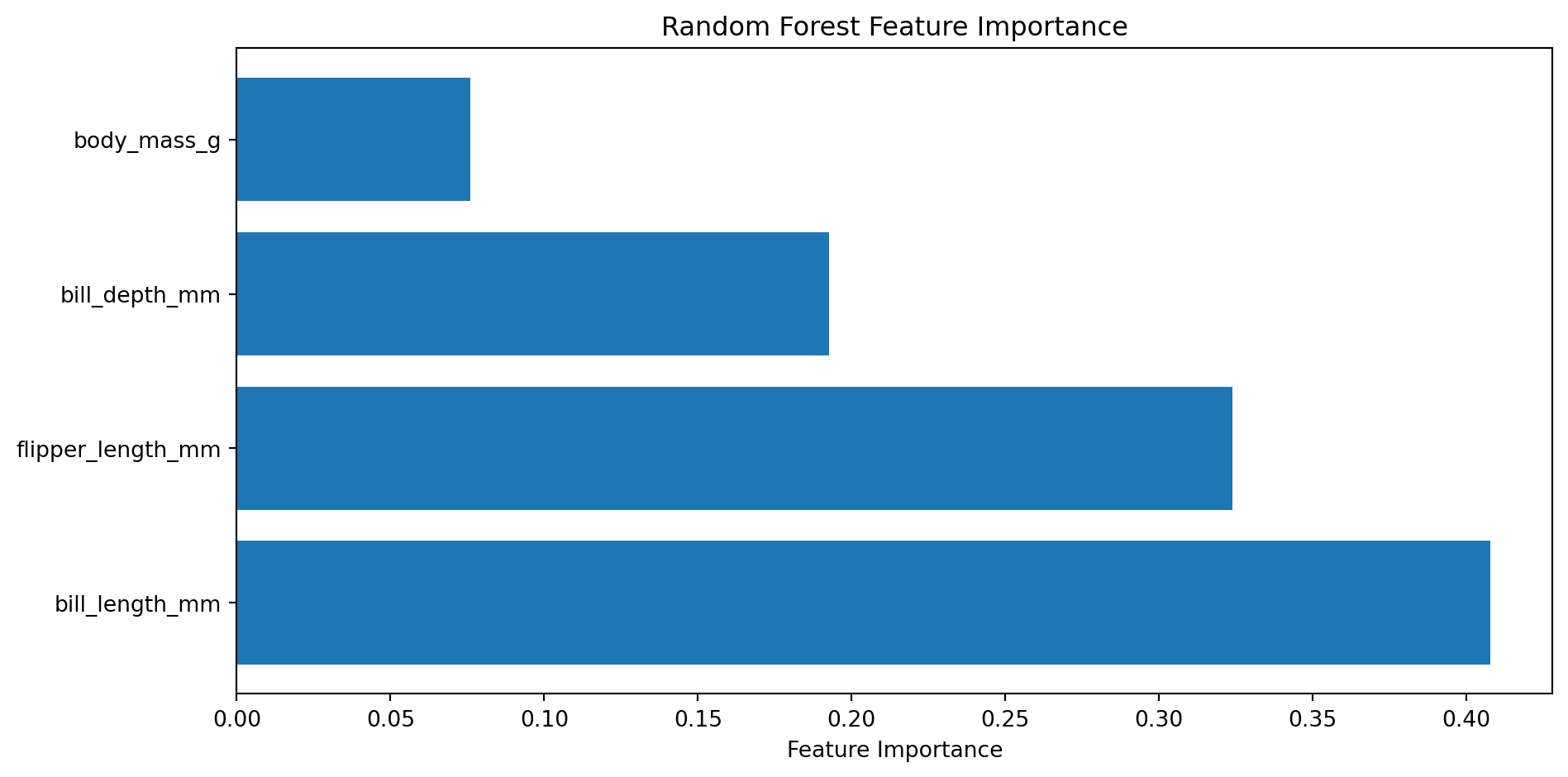
from sklearn.feature_selection import SelectFromModel# 중요도 기반 자동 선택selector = SelectFromModel(rf, threshold='median')X_important = selector.fit_transform(X, y)print(f"\n선택된 변수 수: {X_important.shape[1]}")print(f"선택된 변수: {X.columns[selector.get_support()].tolist()}")
선택된 변수 수: 2
선택된 변수: ['bill_length_mm', 'flipper_length_mm']
20.6 방법별 종합 비교
특성 선택 방법 종합 비교
방법
계산 비용
성능
해석력
모델 의존성
적용 상황
필터
낮음
중간
높음
낮음
대용량, 빠른 탐색
래퍼
매우 높음
높음
중간
높음
소규모, 성능 중시
임베디드
중간
높음
중간
중간
일반적 상황 (권장)
방법 선택 가이드
데이터 크기
├─ 대용량 (변수 100+) → 필터 방법
│ ↓
│ 임베디드 방법으로 정제
└─ 소규모 (변수 < 50) → 래퍼 또는 임베디드
목적
├─ 빠른 탐색 → 필터 (상관계수, SelectKBest)
├─ 최고 성능 → 래퍼 (RFECV)
└─ 균형 잡힌 접근 → 임베디드 (Lasso, 트리 중요도)
20.7 실무 적용 전략
단계별 특성 선택 전략
단계
방법
목적
1단계 (거름망)
분산 기반
분산 없는 변수 제거
2단계 (예비 선택)
필터 (상관계수)
명백히 무관한 변수 제거
3단계 (정제)
임베디드 (트리 중요도)
중요 변수 추출
4단계 (최적화)
래퍼 (RFECV)
최종 조합 선택
5단계 (검증)
교차 검증
성능 확인
예제: 종합 파이프라인
from sklearn.pipeline import Pipeline# 1. 분산 제거var_threshold = VarianceThreshold(threshold=0.01)# 2. SelectKBest (상위 3개)select_k = SelectKBest(f_classif, k=3)# 3. 모델model_final = LogisticRegression(max_iter=1000)# 파이프라인 구성pipeline = Pipeline([ ('variance', var_threshold), ('select', select_k), ('model', model_final)])# 학습 및 평가X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)pipeline.fit(X_train, y_train)print("=== 파이프라인 결과 ===")print(f"학습 정확도: {pipeline.score(X_train, y_train):.4f}")print(f"테스트 정확도: {pipeline.score(X_test, y_test):.4f}")
=== 파이프라인 결과 ===
학습 정확도: 0.9887
테스트 정확도: 1.0000
20.8 요약
이 장에서는 특성 선택의 개념과 세 가지 주요 방법을 학습했다. 주요 내용은 다음과 같다.
특성 선택 핵심 요약
목적: 과적합 방지, 성능 향상, 해석력 증대, 비용 절감
필터: 통계량 기반, 빠르지만 상호작용 고려 못함
래퍼: 모델 성능 기반, 정확하지만 느림
임베디드: 학습 과정에 통합, 균형 잡힌 접근
실무 권장사항
대용량 데이터: 필터 → 임베디드 순서로 적용
소규모 데이터: 임베디드 또는 래퍼 사용
해석 중요: 필터 또는 Lasso 선호
성능 우선: RFECV 또는 트리 중요도 사용
파이프라인 구성: 여러 방법을 순차적으로 조합
주의사항
특성 선택은 데이터 분할 후 학습셋으로만 수행
교차 검증으로 안정성 확인
도메인 지식과 통계적 방법 결합
제거된 변수도 문서화하여 추후 검토
특성 선택은 모델 성능과 해석력을 동시에 향상시키는 강력한 도구이다. 데이터 특성과 목적에 맞는 방법을 선택하고, 여러 방법을 조합하여 최적의 변수 집합을 찾는 것이 중요하다.